写在前面:因为这学期上了软院传奇屎课软工2,为了更好地展示大作业(图书商城)的效果,故写了个爬虫爬取了当当网的数据。
一、获取Cookie
因为不登陆的话当当网是有访问次数限制的,所以需要获取个人Cookie来维持登录状态。Cookie的获取非常简单,只需要在浏览器登录当当网后按下f12打开开发者工具,选择网络后再刷新一下页面,选择其中某一个元素就能查看到Cookie。
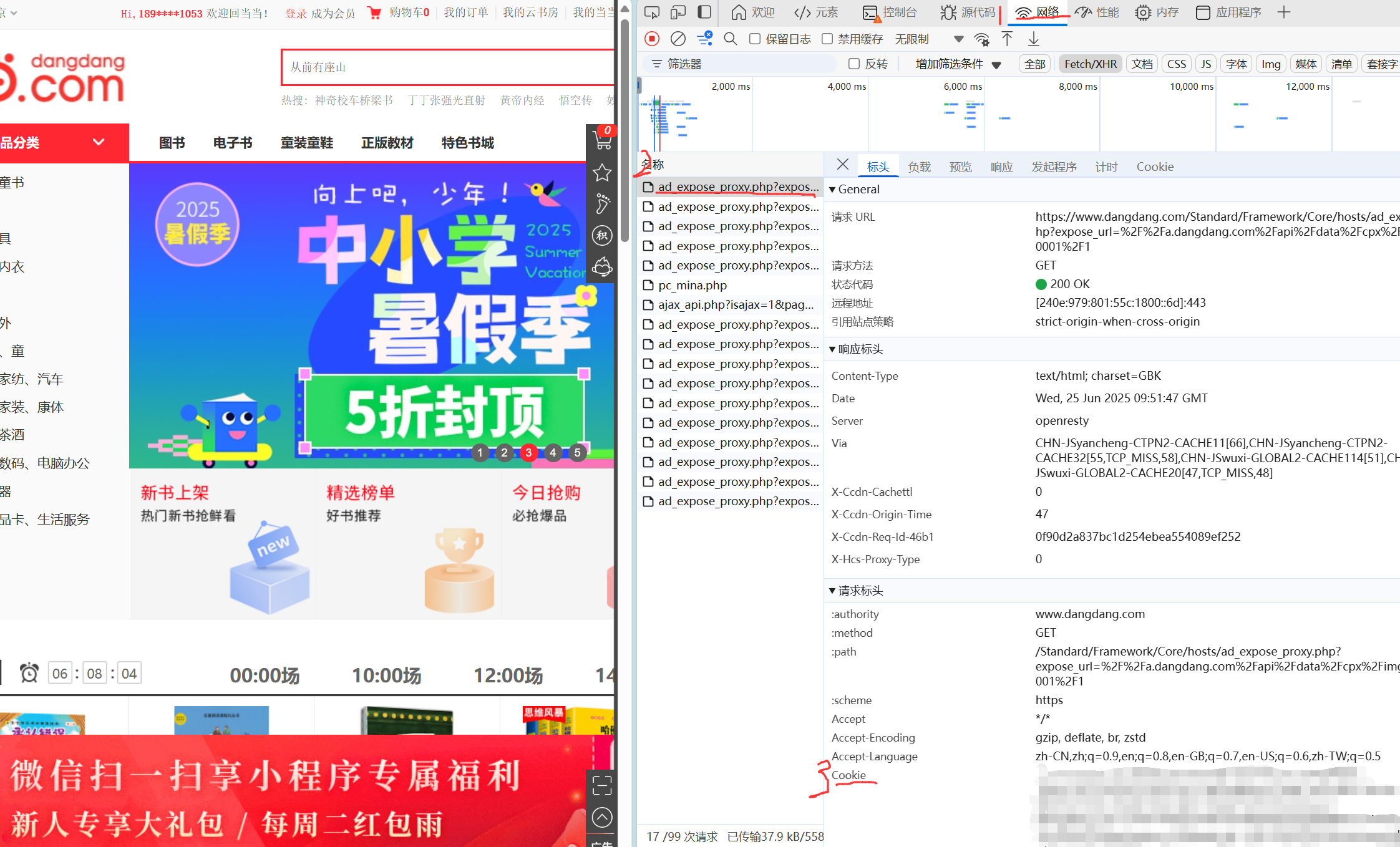
相关的登陆代码大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| def __init__(self):
self.session = requests.Session()
self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
self.session.headers.update(self.headers)
self.load_cookies_from_file()
def load_cookies_from_file(self):
"""从cookie.txt文件加载Cookie数据"""
cookie_file = "cookie.txt"
if os.path.exists(cookie_file):
try:
with open(cookie_file, 'r', encoding='utf-8') as f:
cookie_str = f.read().strip()
if cookie_str:
cookies = {}
for item in cookie_str.split(';'):
if item:
item = item.strip()
if '=' in item:
key, value = item.split('=', 1)
cookies[key] = value
self.session.cookies.update(cookies)
print("已从cookie.txt加载Cookie数据")
else:
print("cookie.txt文件为空")
except Exception as e:
print(f"加载Cookie数据失败: {e}")
else:
print(f"未找到cookie.txt文件,将使用无登录状态访问")
print("提示: 请从浏览器开发者工具中复制Cookie并保存到同目录的cookie.txt文件中")
|
二、分析网页元素
这步更简单,只需要分析网页结构即可(剩下的交给ai)。下面以爬某个商品的图片链接来说明:打开商品详情页面,对准商品图片按下鼠标右键,在选项框里选择“检查”,
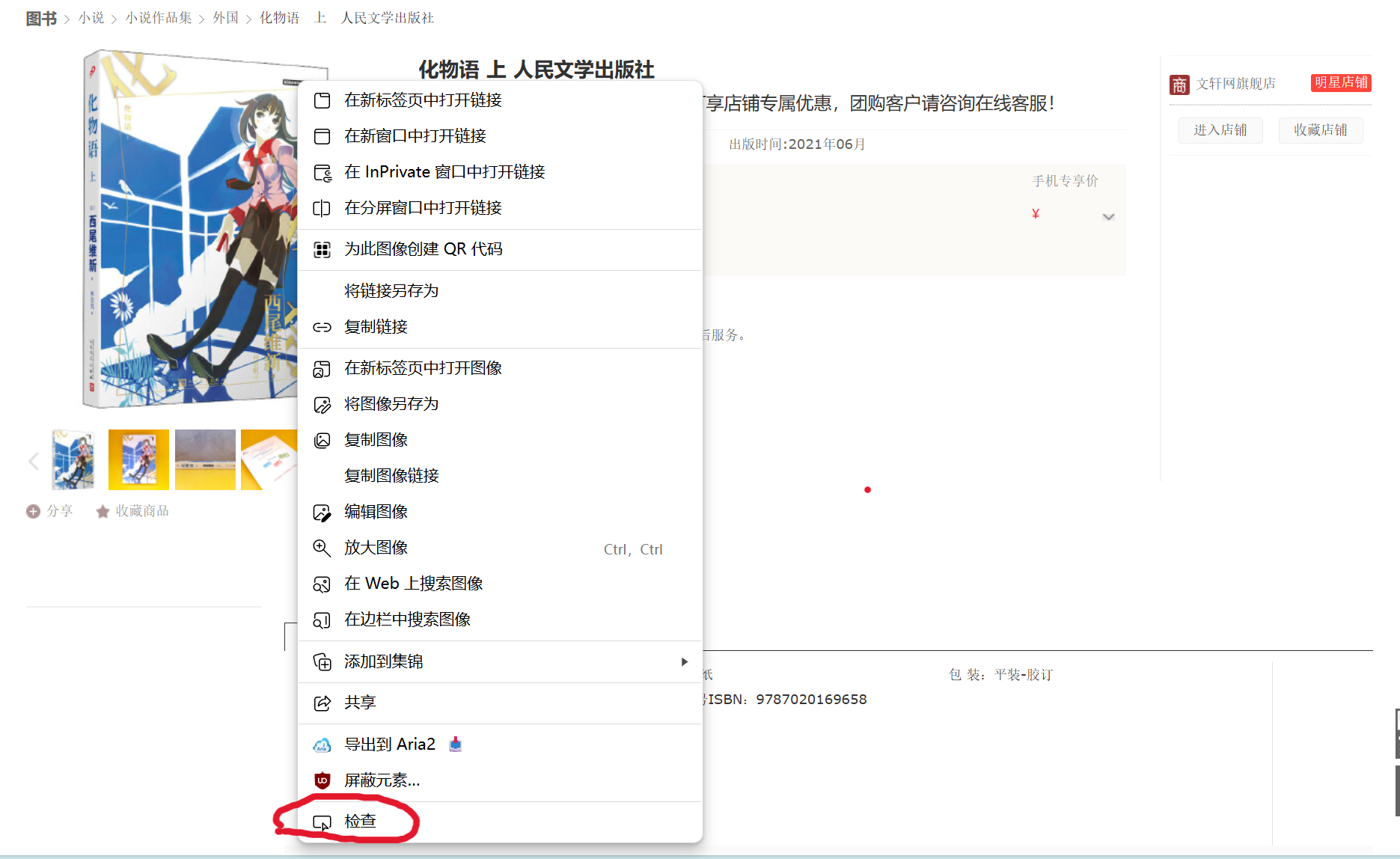
然后在弹出的开发者工具中就会显示图片对应的网页结构,

从html文件中可以看到商品图片对应的模块是id为largePic的img块,我们可以给ai描述为“从id为largePic的img块中获取src的内容,并在链接前面添加‘https:’。”
获取链接的核心代码如下(使用了BeautifulSoup包):
1
2
3
4
| cover_elem = soup.select_one('img#largePic')
if cover_elem and cover_elem.has_attr('src'):
src = cover_elem['src']
product_info["cover"] = f"https:{src}"
|
其余的相关信息也是依法炮制,比如要获取标题信息就对标题进行检查,要获取作者信息就对准作者信息进行检查,这里给出我获取的一些商品信息的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| def extract_product_info(self, url: str) -> Dict[str, Any]:
"""从商品页面提取详细信息"""
soup = self.fetch_page(url)
if not soup:
return None
product_info = {
"title": "",
"price": 0,
"rate": 6,
"description": "",
"cover": "",
"detail": "",
"specifications": [
{"item": "作者", "value": ""},
{"item": "副标题", "value": ""},
{"item": "ISBN", "value": ""},
{"item": "帧装", "value": ""},
{"item": "页数", "value": ""},
{"item": "出版社", "value": ""},
{"item": "出版日期", "value": ""}
]
}
title_elem = soup.select_one('div.name_info h1')
if title_elem and title_elem.has_attr('title'):
full_title = title_elem['title']
if isinstance(full_title, list):
full_title = ''.join(full_title)
if '(' in full_title:
product_info["title"] = full_title.split('(')[0]
elif '(' in full_title:
product_info["title"] = full_title.split('(')[0]
elif ' ' in full_title:
product_info["title"] = full_title.split(' ')[0]
else:
product_info["title"] = full_title
price_elem = soup.select_one('p#dd-price')
if price_elem:
try:
price_text = ''.join(c for c in price_elem.text if c.isdigit() or c == '.')
product_info["price"] = float(price_text)
except ValueError:
pass
desc_elem = soup.select_one('span.head_title_name')
if desc_elem and desc_elem.has_attr('title'):
product_info["description"] = desc_elem['title']
cover_elem = soup.select_one('img#largePic')
if cover_elem and cover_elem.has_attr('src'):
src = cover_elem['src']
product_info["cover"] = f"https:{src}"
messbox = soup.select_one('div.messbox_info')
if messbox:
spans = messbox.select('span')
if len(spans) > 0:
author_elem = spans[0].select_one('a')
if author_elem:
product_info["specifications"][0]["value"] = author_elem.text.strip()
if len(spans) > 1:
publisher_elem = spans[1].select_one('a')
if publisher_elem:
product_info["specifications"][5]["value"] = publisher_elem.text.strip()
if len(spans) > 2:
product_info["specifications"][6]["value"] = spans[2].text.split(':', 1)[1].strip()
key_ul = soup.select_one('ul.key.clearfix')
if key_ul:
lis = key_ul.select('li')
if len(lis) > 2:
framing_text = lis[2].text.strip()
product_info["specifications"][3]["value"] = framing_text.split(':', 1)[1].strip()
if len(lis) > 4:
isbn_text = lis[4].text.strip()
product_info["specifications"][2]["value"] = isbn_text.split(':', 1)[1].strip()
return product_info
|
一点儿吐槽:ai是真好用啊,感觉我不如ai一根。当当网的网页结构是真的丑,甚至每本书各自的标签爬下来和主页的标签分类对不上,还要手动调整,也是被整无语了。




