C++中的类: 构造与析构
类
类的定义如下,以简单的TDate为例:
1 | class TDate { |
- 在类中定义且实现了的函数(
SetDate(),IsLeapYear())编译器会自动内联,即隐式内联。 - 不能在类中直接像
int year = 2000这样初始化函数(C++11前,之后可以对非静态成员这样进行初始化),需要定义构造函数来进行初始化:TDate() : year(2000) {}。
如果要实现ADT的话(头文件 / 源文件分离),实现如下:
在a.h中定义类:
1 | class TDate { |
在a.cpp中实现函数:
1 | void TDate::SetDate(iny y, int m, int d) { |
- 因为函数只是声明在
.h,具体实现放在.cpp,编译器在编译使用处看不到函数体,通常不能在编译期内联(所以不会被内联)。 - 重要的是需要声明命名空间(
namespace)为TDate。
构造函数
构造函数用于对象的初始化,主要特点:与类同名且无返回类型;自动调用但不可直接调用;可重载。
默认构造函数
编译器只有在类没有“用户声明的构造函数”(即你没写任何构造函数)的情况下才会隐式声明一个默认构造函数(default constructor)。
即便被隐式声明了,若类的某个基类或非静态成员没有可用的默认构造函数(或是引用const成员无初始值等),该默认构造函数会被定义为deleted(不可用)。
例子如下:
1 | // 有隐式默认构造 |
调用
1 | class A { |
成员初始化表
- 成员初始化表是构造函数的补充,当成员是
const、引用(T&)、或类型没有默认构造(只有带参构造),以及需要用特定构造函数初始化的成员对象;这些必须用初始化表初始化,否则编译错误。同时,初始化表直接调用成员的构造函数(直接初始化);在构造函数体内赋值则是先调用默认构造再赋值(多一步、可能不可行),能够减轻compiler的负担。 - 执行顺序:优先于构造函数体,按类数据成员申明次序来进行:虽然z写在x前面进行初始化,但是因为x先声明所以不会报错;如果y在函数体内初始化会报错但是在初始化表里不会报错;x的值最后等于100。
1
2
3
4
5
6
7class A {
int x;
const int y;
int &z;
public:
A() : y(1), z(x), x(0) {x = 100;};
}
成员初始化
- 就地成员初值:x最后会被赋值为42(初始化表优先级更高会覆盖默认值)。
1
2
3
4struct S {
int x = 0;
S() : x(42) {}
} - 统一初始化(Uniform initialization):虽然使用花括号能够统一初始化的风格,但是和=以及()进行赋值也是有差别的,第一个就是窄化检查:
1
2
3int x{0}; // 标量
std::vector<int> v{1, 2}; // 容器
S s{1, "abc"}; // 聚合或匹配构造第二个就是对于定义了1
2
3
4double d = 3.14;
int a(d); // 静默截断
int b = d; // 静默截断
int c{d}; // 报错:窄化std::initializer_list构造函数的类,用花括号{}初始化时会优先匹配这个构造函数:1
2
3
4
5
6
7struct B {
B(int, int);
B(std::initializer_list<int>);
};
B b1{1, 2}; // 调用 B(std::initializer_list<int>)
B b2(1, 2); // 调用 B(int, int)
一般来说,const / 引用 / 没有默认构造的成员 / 基类构造必须使用成员初始化表;推荐复杂成员(string, vector, 自己的类)使用初始化表因为更高效;希望防窄化、更统一风格时使用花括号:int x{0};、S s{arg1, arg2};对有自然默认值的成员推荐使用就地成员默认值。
析构函数
析构函数释放对象持有的资源(堆内存资源、文件句柄、锁、socket等),以及配合new/delete管理堆内存。
- 定义方式:
~<类名>():1
2
3
4
5
6
7class A {
private:
char* str;
public:
A() : str(nullptr) {}
~A() { delete[] str; }
}; - 对象生命周期结束时(栈对象离开作用域,或对堆对象执行
delete等),系统都会自动调用该对象的析构函数;栈对象的结束时机由作用域决定,堆对象的结束时机由程序员负责调用delete或使用智能指针(unique_ptr)控制。
GC与RAII
GC(Garbage Collection)
典型语言:Java、C#等
- GC管理的是内存:当对象不再被引用时,由运行时系统自动回收内存。
- 程序员不用写
delete,减少内存泄漏、悬挂指针风险。 - 但GC:
- 不适合同步、实时要求高的场景(停顿、不可控回收时机)。
- 只负责内存,不会自动关闭文件、释放锁、断开网络连接——这些仍需你写显式的
close()/dispose()等。
有些场景(高性能、实时系统等)不能依赖GC,需要程序员自己控制资源释放。
RAII(Resource Acquisition Is Initialization)
典型语言:C++
核心思想:
“获取资源 = 构造对象;释放资源 = 析构对象”。实现方式:
- 在构造函数中获取资源(
new、fopen、lock等); - 在析构函数中自动释放资源(
delete、fclose、unlock等); - 利用作用域结束时自动调用析构函数来保证“用完必释放”,无论函数正常返回还是抛异常。
- 在构造函数中获取资源(
优点:
- 不需要GC,也不需要手动到处写
close(),异常也不怕。 - 不仅可以管理“内存”,还可以管理“一切需要成对获取/释放的资源”。
- 不需要GC,也不需要手动到处写
一个有趣的问题:如何创建只能在堆/栈上申请空间的类?
只在堆上创建
只在堆上创建,就是要避免出现A a这种情况,一个很简单的思路就是禁止外部直接调用构造/析构,只能通过工厂函数在堆上创建。
1 | class HeapOnly { |
只能在堆上创建的好处就是堆上空间大,如果你这个类占用内存很大强制在堆上创建的话不用担心栈溢出的问题。
只在栈上创建
只在栈上创建,就是要避免出现A* a = new A()这种情况,一个很简单的思路就是禁止对该类型使用 new/delete,只允许自动存储(A a;作为成员/局部变量)。
1 | class StackOnly { |
只能在栈上创建好处当然就是反过来,并且栈上分配空间速度快于堆上分配空间,所以在栈上创建适用于小内存的类。
拷贝构造函数
用同类型的已有对象来初始化新对象时会调用拷贝构造函数(例如A b = a;),这是由编译器在需要的时候自动调用的。
常见的触发场景:
- 直接初始化:
A a; A b = a; - 传值调用:
f(A a) {}; A b; f(b); - 函数值返回:
A f() { A a; return a; }
默认拷贝构造函数
- 逐个成员初始化(member-wise initialization / member-wise copy),也就是对每个成员执行其拷贝构造或按位复制(对内置/指针类型为浅拷贝)。
- 对于成员对象,拷贝过程是递归的(成员对象各自按其拷贝规则复制)。
何时需要自定义拷贝构造函数
如果类持有裸指针或资源,默认的浅拷贝可能导致双重释放等问题——此时需自定义拷贝构造(或实现拷贝/移动语义、使用智能指针)。
例子:
1 | class string { |
因为没有定义拷贝构造函数,这里s2会进行默认拷贝构造(是浅拷贝,s2的值为s1指针值)。
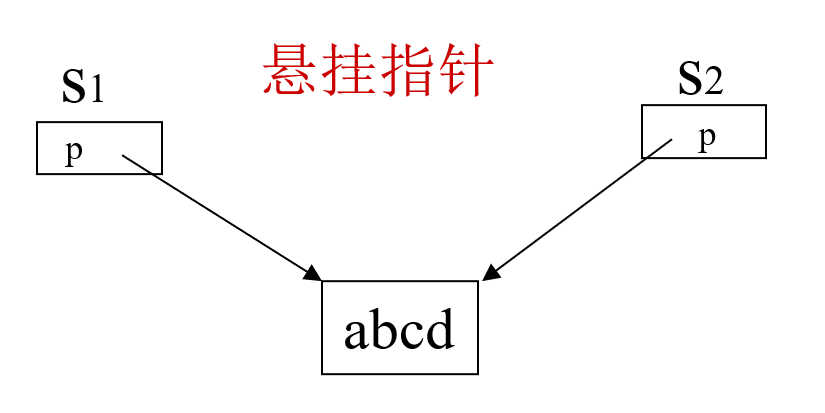
如图所示两个指针指向同一个字符串,当s1释放资源时s2就会成为悬挂指针。修改方案是将默认的浅拷贝自定义为深拷贝:
1 | string::string(const string& s) { |
先重新分配空间,再依次复制。
注意的一点是默认拷贝构造函数是直接调用的成员对象的拷贝构造函数但是自定义拷贝构造函数是调用成员对象的默认构造函数然后再赋值,所以在一个类中要初始化为另一个类的成员对象需要放在初始化表里,在之前的成员初始化表里也提到过。
1 | // A 没有默认构造 |
为什么使用const T&
效率:
T&不会复制对象(避免昂贵的拷贝),只传递引用且不使用&来传递引用会导致递归。通用性:
const T&可以绑定到左值和右值(临时对象),所以既能接收已有对象也能接收临时结果。比如:1
2
3// 函数返回的是一个临时对象,使用T&会报错
string generate() { return string("test"); }
string s = generate();安全性:
const保证函数不能修改被引用的对象,表达意图并避免意外修改。
移动构造函数
移动构造函数比拷贝构造函数更快,因为只是拷贝指针。
右值引用
左值(l‑value):有一个稳定的存储位置(地址),程序在之后还能通过这个名字再访问它。
右值(r‑value):只是一个计算结果,没有独立的持久存储位置,一般是临时值。
1 | a = 1 + 2; // a是左值,1+2是右值 |
在C++中,非常量引用可以绑定到左值,常量引用可以绑定到左值或右值。这点已经在之前讲const T&的时候讲过了。
右值引用可以绑定到右值,右值引用T&&来表示:
1 | class A { |
移动构造函数注意点
要把参数的指针设置为
nullptr:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class MyArray {
int size;
int *arr;
public:
MyArray() : size(0), arr(nullptr) {}
MyArray(int sz) : size(sz), arr(new int[sz]) {}
// 拷贝构造函数
MyArray(const MyArray &other) :
size(other.size), arr(new int[other.size]) {
for (int i = 0; i < size; ++i)
arr[i] = other.arr[i];
}
// 移动构造函数
MyArray(MyArray &&other) :
size(other.size), arr(other.arr) {
other.arr = nullptr; // 避免双重释放
}
~MyArray() { delete[] arr; }
}当输入的是一个右值时会优先匹配移动构造而不是拷贝构造,因为编译器会匹配更符合语义的构造函数:
1
2
3
4MyArray a;
MyArray b = a; // a 是左值,只能调用拷贝构 MyArray(const MyArray&)
MyArray c = MyArray(); // MyArray() 是右值,优先调用 MyArray(MyArray&&)
MyArray d = std::move(a); // std::move(a) 是右值,也优先调用 MyArray(MyArray&&)使用移动构造函数的时候要注意一个坑:形参虽然是
T&&,但一旦有了名字,在函数体内它就是左值。如果想把它继续当右值传给别的函数,需要用std::move():1
2
3
4
5
6void process(int&& r) {}
void handle(int&& rvalue) {
// rvalue在这里是一个有名字的变量,因此是左值
// process(rvalue); // 编译错误:需要右值
process(std::move(rvalue)); // 正确:强制把rvalue当成右值
}
RVO与NRVO
理论上,函数按值返回局部对象时,需要一次(或两次)拷贝/移动:
1 | // 使用之前定义过的MyArray |
RVO/NRVO能直接在调用者那块内存上构造返回对象,从而连拷贝 / 移动构造都省掉;
如果某些场景不能做RVO,才会退而求其次用移动构造(有T(T&&)时)或拷贝构造(有T(const T&)时)。



去听サイエンス谢谢喵ヾ(=`ω´=)ノ”

